

Meta has taken another step forward with its AI plans, with the launch of its Llama 4 AI models, which, in testing, have proven to provide better performance on virtually all fronts than its competitors.
Well, at least based on the results that Meta’s chosen to release, but we’ll get to that.
First off, Meta’s announced four new models that include much larger systematic training and parameter inference than previous Llama models.
Meta’s four (yes, four, the last one is not featured in this image) new Llama models are:
- Llama 4 Scout immediately becomes the fastest small model available, and has been designed to run on a single GPU. Scout includes 17 billion parameters and 16 experts, which enables the system to optimize its responses based on the nature of each query.
- Llama 4 Maverick also includes a 17 billion parameter resource, but also incorporates 128 experts. The use of “experts” means that only a subset of the total parameters are activated for each query, improving model efficiency by lowering model serving costs and latency. That means that developers utilizing these models can get similar results with less compute.
- Llama 4 Behemoth includes more than 2 trillion parameters, making it the largest system currently available. That, at least in theory, gives it much more capacity to be able to understand and respond to queries with advanced learning and inference.
- Llama 4 Reasoning is the final model, which Meta hasn’t shared much info on as yet.
Each of these models serves a different purpose, with Meta releasing variable options that can be run with less or more powerful systems. So if you’re looking to build your own AI system, you can use Llama Scout, the smallest of the models, which can run on a single GPU.
So what does this all mean in layman’s terms?
To clarify, each of these systems is built on a range of “parameters” that have been established by Meta’s development team to improve systematic reasoning. Those parameters are not the dataset itself (which is the language model) but the amount of controls and prompts built into the system to understand the data that it’s looking at.
So a system with 17 billion parameters will ideally have a better logic process than one with fewer parameters, because it’s asking questions about more aspects of each query, and responding based on that context.
For example, if you had a four parameter model, it would basically be asking “who, what, where, and when”, with each additional parameter adding more and more nuance. Google Search, as something of a comparison, utilizes over 200 “ranking signals” for each query that you enter, in order to provide you with a more accurate result.
So you can imagine how a 17 billion parameter process would expand this.
And Llama 4’s parameters are more than double the scope of Meta’s previous models.
For comparison:
So, as you can see, over time, Meta’s building in more system logic to ask more questions, and dig further into the context of each request, which should then also provide more relevant, accurate responses based on this process.
Meta’s “experts”, meanwhile, are a new element within Llama 4, and are systematic controls that define which of those parameters should be applied, or not, to each query. That reduces compute time, while still maintaining accuracy, which should ensure that external projects utilizing Meta’s Llama models will be able to run them on lower spec systems.
Because literally nobody has the capacity that Meta does on this front.
Meta currently has around 350,000 Nvidia H100 chips powering its AI projects, with more coming online as it continues to expand its data center capacity, while it’s also developing its own AI chips that look set to build on this even further.
OpenAI reportedly has around 200k H100s in operation, while xAI’s “Colossus” super center is currently running on 200k H100 chips as well.
So Meta is likely now running at double the capacity of its competitors, though Google and Apple are also developing their own approaches to the same.
But in terms of tangible, available compute and resources, Meta is pretty clearly in the lead, with its latest Behemoth model set to blow all other AI projects out of the water in terms of overall performance.
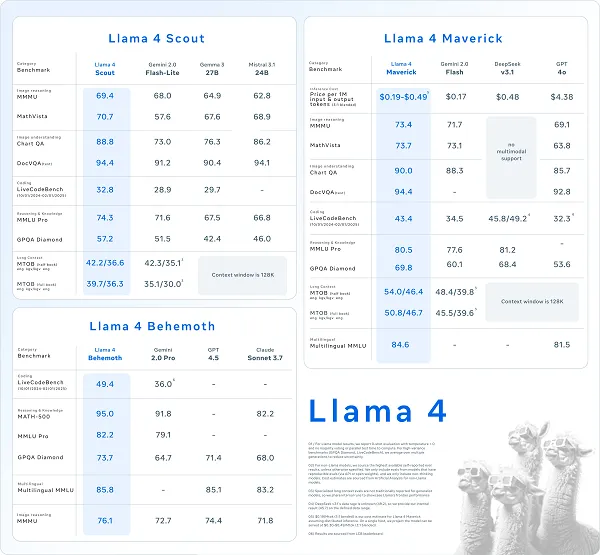
You can see a comparison of comparative performance between the major AI projects in this chart, though some questions have also been raised as to the accuracy and applicability of Meta’s testing process, and the benchmarks it’s chosen to match its Llama models against.
It’ll come out in testing, and in user experience either way, but it is also worth noting that not all the results produced by Llama 4 have been as mind-blowing as Meta’s seems to suggest.
But overall, it is seemingly driving better results, on all fronts, while Meta also says that the lower entry models are cheaper to access, and better, than the competition.
Which is important, because Meta’s also open sourcing all of these models for use in external AI projects, which could enable third-party developers to build new, dedicated AI models for varying purpose.
It’s a significant upgrade either way, which stands to put Meta on the top of the heap for AI development, while enabling external developers to utilize its Llama models also stands to make Meta the key load-bearing foundation for many AI projects.
Already, LinkedIn and Pinterest are among the many systems that are incorporating Meta’s Llama models, and as it continues to build better systems, it does seem like Meta is winning out in the AI race. Because all of these systems are becoming reliant on these models, and as they do, that increases their reliance on Meta, and its ongoing Llama updates, to power their evolution.
But again, it’s hard to simplify the relevance of this, given the complex nature of AI development, and the processes that are required to run such.
For regular users, the most relevant part of this update will be the improved performance of Meta’s own AI chatbot and generation models.
Meta’s also integrating its Llama 4 models into its in-app chatbot, which you can access via Facebook, WhatsApp, Instagram, and Messenger. The updated system processing will also become part of Meta’s ad targeting models, its ad generation systems, its algorithmic models, etc.
Basically, every aspect of Meta’s apps that utilize AI will now get smarter, by using more logical parameters within their assessment, which should result in more accurate answers, better image generations, and improved ad performance.
It’s difficult to fully quantify what this will mean on a case-by-case basis, as individual results may vary, but I would suggest considering Meta’s Advantage+ ad options as an experiment to see just how good its performance has become.
Meta will be integrating its latest Llama 4 models over the coming weeks, with more upgrades still coming in this release.

